

Der vorliegende Beitrag entstand im Rahmen der Sommerakademie «Stupid Statistics?!? Durchblick behalten im Daten-Dschungel der Gegenwart» der Schweizerischen Studienstiftung und wurde redaktionell begleitet von Reatch.
In einer Welt, in der Zahlen und Daten allgegenwärtig sind, wächst die Notwendigkeit einer kritischen Statistik-Kompetenz. Sie hilft dabei, Fallstricke und Manipulationen in Statistiken zu erkennen und so die Grundlagen einer informierten Gesellschaft zu festigen.
In einer Welt, in der mehr Daten gesammelt und verarbeitet werden als je zuvor, treten auf den ersten Blick die interessantesten und kuriosesten Zusammenhänge zutage. So nimmt scheinbar mit dem Pro-Kopf-Konsum von Mozzarella die Anzahl der verliehen Doktortitel im Bauingenieurwesen in den USA zu, während die Anzahl der Doktortitel in Mathematik auf den ersten Blick mit der Menge von in US-Kernkraftwerken gelagertem Uran in Verbindung steht. Klingt absurd? Ist es auch, aber mithilfe von statistischen Methoden lässt sich eine hohe Korrelation zwischen diesen Größen nachweisen.[1] Dies lässt jedoch nicht auf einen kausalen Zusammenhang schliessen, da kein plausibler Grund bekannt ist, warum der nationale Käsekonsum und die Menge verliehener Doktortitel sich gegenseitig beeinflussen sollten. Die genannten Beispiele korrelieren also zufällig miteinander, was in der Statistik als Nonsens-Korrelation bezeichnet wird. Solche Nonsens-Korrelationen sind aber nicht immer derart offensichtlich als solche zu erkennen, sondern werden zum Teil in seriösen Print- und Onlinemedien veröffentlicht und dienen als Grundlage der Meinungsbildung vieler Menschen.
In der jüngsten Vergangenheit finden sich zahlreiche Beispiele für solche politisch und medial brisanten, jedoch irreführenden Korrelationen. Im Zuge der Coronapandemie wurde beispielsweise im Mai 2022 eine britische Studie veröffentlicht, die Risikofaktoren im Zusammenhang mit Covid-19-Todesfällen untersuchte. Die Studie ermittelte unter anderem eine geringere Sterberate bei Raucher*innen. Obwohl Epidemiolog*innen und auch einer der Studienautoren darauf hinwiesen, dass sich daraus nicht ableiten lasse, dass Nikotin vor Covid-19 schützt, wurde in britischen Medien über einen „schützenden Effekt“ des Rauchens spekuliert. Solche Interpretationen lassen wichtige Kontextinformationen und die Möglichkeit von zufälligen Schwankungen oder systematischen Verzerrungen unerwähnt.[2]
Dieses häufig in der Covid-19-Berichterstattung auftretende Problem ist der sogenannte „ökologische Fehlschluss“, bei dem Rückschlüsse auf die Eigenschaften oder Risiken von Einzelpersonen basierend auf Bevölkerungsdaten gezogen werden. Ein typisches Beispiel für einen solchen Fehlschluss ist die kausale Verknüpfung von Feinstaubbelastung und Covid-19, ohne weitere Faktoren zu berücksichtigen. Es ist wichtig zu betonen, dass solche Assoziationen nicht notwendigerweise falsch sind – sie bedürfen jedoch einer sorgfältigeren Prüfung und Analyse. Beispielsweise sind Gebiete mit hoher Feinstaubbelastung oft dicht besiedelte, urbanisierte und international vernetzte Regionen, in denen das Virus sich wahrscheinlich schneller verbreitet. Die erhöhte Anzahl von Todesfällen könnte also ebenso auf eine erhöhte Verbreitung des Virus in diesen Gebieten zurückzuführen sein, und nicht unbedingt direkt auf die Luftverschmutzung. Ebenso könnte der geringere Anteil von Raucher*innen unter den COVID-19-Todesfällen auf die generell niedrigere Raucher*innenquote unter älteren Menschen zurückzuführen sein, die ein höheres Risiko für einen schweren Verlauf von COVID-19 haben. Das bedeutet, dass die niedrigere Sterberate bei Raucher*innen auch auf demografische Faktoren und nicht unbedingt auf eine schützende Wirkung des Rauchens zurückzuführen sein könnte.[3]
Diese Fehlinterpretationen und das Ignorieren alternativer Erklärungen können zu irreführenden und potenziell schädlichen Schlussfolgerungen führen und einen erheblichen Einfluss auf den öffentlichen Diskurs haben. Es ist von entscheidender Bedeutung, dass die Ergebnisse wissenschaftlicher Studien mit Sorgfalt und kritischem Denken interpretiert und kommuniziert werden, um falsche Annahmen und Fehlinformationen zu vermeiden.
Wenn das statistische Verständnis fehlt, um zwischen Korrelation und Kausalität zu unterscheiden und Studien selbst kritisch einordnen zu können, so kann dies gerade bei kontroversen Themen wie Covid-19 rasch zu einer Verbreitung von Fehlinformation führen. Auch können irreführende Statistiken zu einem Vertrauensverlust in wissenschaftliche Expertise beitragen, was dazu führt, dass Menschen skeptischer gegenüber Ratschlägen von Gesundheitsexpert*innen oder der wissenschaftlichen Gemeinschaft im Allgemeinen werden. Um dies zu verhindern, ist der Aufbau eines guten statistischen Grundverständnis in der gesamten Gesellschaft unerlässlich.
Warum ist “Data Literacy” wichtig?
In einer durch Algorithmen und Informationsflut geprägten Welt rückt Datenkompetenz (engl. “Data Literacy”) immer stärker in den Vordergrund. Gemeint ist damit die Fähigkeit, Daten zu verstehen, zu bewerten und effektiv zu nutzen. In einer Ära, die von Daten in allen erdenklichen Formen durchdrungen ist, hilft Datenkompetenz Bürger*innen dabei, informierte Entscheidungen zu treffen und am demokratischen Diskurs teilzunehmen. Sie ermöglicht es, zwischen glaubwürdigen Quellen und Fehlinformationen zu unterscheiden, kritisch mit Informationen umzugehen und Statistiken sachgemäss zu interpretieren.
Damit leistet Datenkompetenz einen unverzichtbaren Beitrag zur politischen Mündigkeit. Sie gibt Wähler*innen die Werkzeuge an die Hand, um öffentliche Daten zu prüfen und zu hinterfragen, beispielsweise um die Entscheidungen und Handlungen der Regierung anhand von verfügbaren Daten zu überprüfen und so ein Verständnis für die Abläufe und die Rechtmäßigkeit der Institutionen zu entwickeln. Diese Fähigkeit stärkt das Vertrauen in demokratische Institutionen[4] und fördert eine informierte Wählerschaft, was wiederum die Qualität politischer Entscheidungsfindung verbessert und die Stabilität der Demokratie selbst festigt.
Die Fähigkeit, statistische Grundkonzepte zu begreifen, Datenvisualisierungen zu deuten und vor allem den Kontext zu berücksichtigen, ist somit nicht nur eine individuelle Befähigung, sondern vielmehr das Fundament für eine robuste und prosperierende Demokratie. Im digitalen Zeitalter, in dem wir uns bewegen, erweist sich die Förderung der Datenkompetenz somit als integraler Bestandteil des Fortbestehens und der Resilienz unserer demokratischen Gesellschaft. In einer Welt, die von Daten dominiert wird, wird die Datenkompetenz zur Währung der demokratischen Teilhabe.
Welche statistischen Kenntnisse brauchen Bürger*innen in Demokratien?
Damit Bürger*innen Statistiken kritisch einordnen und irreführende Informationen als solche erkennen können, müssen sie mit statistischen Grundbegriffen vertraut sein, statistische Modellbildung und Datenerhebung nachvollziehen sowie Statistiken kritisch in ihrem Kontext betrachten können.[5] Diese Fertigkeiten bauen aufeinander auf und lassen sich wie folgt in Form einer Pyramide darstellen:
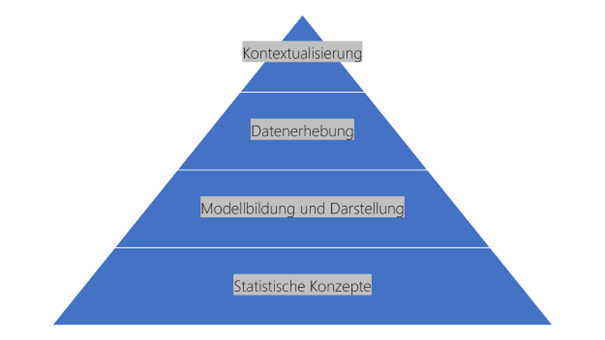
Essenziell für den kompetenten Umgang mit Statistiken ist erstens ein Grundverständnis von zentralen statistischen Konzepten. Lagemasse wie Median und Mittelwert sowie Streumasse wie Standardabweichung und Interquartilsabstand verschaffen einen ersten Überblick über die Beschaffenheit der Daten. Streumasse vermitteln einen Eindruck davon, wie gross der Abstand zwischen hohen und niedrigen Datenpunkten ist. Lagemasse geben Auskunft über Höhe und Verteilung der Werte: Liegt beispielsweise der Median niedriger als der Mittelwert, handelt es sich um eine linksschiefe Verteilung, das heisst, die Stichprobe enthält besonders viele hohe Werte. Bezogen auf die Vermögensverteilung bedeutet dies etwa, dass es in einer Population viele reiche und vergleichsweise wenige arme Menschen gibt. In der Realität ist der umgekehrte Fall jedoch deutlich häufiger: Meist ist die Vermögensverteilung rechtsschief, viele Werte liegen im niedrigen Bereich:

Ist die Verteilung der Datenpunkte grob erfasst, gilt es zu beachten, welchen Zweck die Statistik verfolgt: Während die beschreibende Statistik Daten lediglich visualisiert, versucht die schliessende Statistik, generalisierbare Rückschlüsse aus den Daten zu ziehen. Dabei wird mit Stichproben gearbeitet: Beispielsweise könnte die Vermögensverteilung unter 1000 zufällig ausgewählten Einwohner*innen der Schweiz repräsentativ für die Vermögensverteilung in der gesamten Schweiz stehen. Wahrscheinlichkeits- und Stichprobentheorie liefern dabei die nötigen Grundlagen, um die Auswahl der Stichprobe und die Verlässlichkeit der Schlussfolgerungen zu begründen. Sich mit solchen Konzepten auseinanderzusetzen, verschafft Bürger*innen das nötige Rüstzeug dafür, Statistiken nachvollziehen und ihnen die gewünschten Informationen entnehmen zu können.
Zweitens sollten Bürger*innen in der Lage sein, Modellbildung und Darstellung von Statistiken kritisch zu hinterfragen. Neben der Kenntnis statistischer Konzepte ist dafür die generelle Einsicht wichtig, dass ein und dasselbe Phänomen sich auf unterschiedliche Weisen analysieren und abbilden lässt. Die zugrundeliegenden Definitionen können vom Alltagsverständnis abweichen und entscheidenden Einfluss auf die Ergebnisse haben: So lässt sich etwa Armut einerseits anhand des Durchschnittseinkommens beschreiben, andererseits kann das Medianeinkommen zur Orientierung bei der Definition dienen.[6] Das Durchschnittseinkommen wird als Summe aller Werte geteilt durch die Zahl der Beobachtungen berechnet. Daher ist es anfällig für Ausreisser: Besitzen in einer zehnköpfigen Gruppe neun Personen CHF 10, eine Person aber CHF 1.000.000, so liegt das durchschnittliche Vermögen bei CHF 100.009. Der Median ist derjenige Wert, der “in der Mitte” liegt, wenn alle Werte der Grösse nach sortiert werden. Statistische Ausreisser fallen hier nicht ins Gewicht: Im Beispiel liegt der Median bei CHF 10. Je nach Prozentanteil des Durchschnitts- oder Medianeinkommens, an dem sich die Armutsgrenze orientiert, variieren die statistischen Ergebnisse zusätzlich. Ausserdem gibt es die absolute Armutsgrenze, die von einem finanziellen Existenzminimum ausgeht, und die relative Armutsgrenze, die eine Person dann als arm klassifiziert, wenn deren Einkommen deutlich niedriger ist als das der Bevölkerungsmehrheit.[7] Dies zeigt: Armut lässt sich statistisch unterschiedlich erfassen. Sich des Einflusses von Vorentscheidungen in der Modellbildung bewusst zu sein, ist zentral dafür, die Aussagekraft einer Statistik zu beurteilen.
Drittens stellt sich die Frage, wie die statistischen Daten gesammelt wurden. Bürger*innen sollten die Vor- und Nachteile bestimmter Datenerhebungsmethoden einschätzen und deren Konsequenzen für die Qualität des Datenmaterials abwägen können. In einigen Fällen könnten auch ethische Überlegungen in die Beurteilung einfliessen: Im Jahr 2018 kam es zum Skandal, als sich herausstellte, dass im US-Wahlkampf von 2016 Facebook-Nutzer*innen mit personalisierten Inhalten gezielt zur Wahl von Donald Trump bewegt werden sollten.[8] Die Basis dafür bildeten Daten von 87 Mio. Facebook-Nutzer*innen, die zwischen 2007 und 2014 Daten über eine Quiz-App an das politische Beratungsunternehmen Cambridge Analytica gelangt waren.[9] Ganz abgesehen davon, dass die Daten zu manipulativen und damit demokratiefeindlichen Zwecken eingesetzt wurden, hätten sie in dieser Form gar nicht erhoben werden dürfen: Die Nutzer*innen waren nicht ausreichend über die Datenerhebung in Kenntnis gesetzt worden und hatten folglich keine Gelegenheit, ihr informiertes Einverständnis zu geben. Daten, die unter solch fragwürdigen Umständen gesammelt wurden, sollten in einem demokratischen Diskurs nicht verwendet werden.
Zuletzt ist es für die Beurteilung von Statistiken wichtig, sie in einen grösseren Kontext stellen zu können. Viele Statistiken haben den Anspruch, komplexe soziale Phänomene zu erfassen. Je mehr Hintergrundinformationen zur Verfügung stehen, desto leichter fällt es, die Plausibilität der statistischen Darstellung einzuschätzen. Dabei hilft einerseits ein breites Vorwissen, andererseits die Fähigkeit, sich durch selbständige Recherchen passende Informationen anzueignen. Um beispielsweise Statistiken zur Vermögensverteilung in der Schweiz besser einzuordnen, können Informationen zur Geschichte des Landes oder zu seinem wirtschaftlichen und politischen System hilfreich sein. Vor diesem Hintergrund ergeben sich Fragen wie: Wird die Schere zwischen Arm und Reich in den letzten Jahren grösser? Welche politischen Entscheidungen haben die Vermögensverteilung wie beeinflusst? Erst in Verbindung mit dem Kontext erlauben Statistiken Rückschlüsse auf solche Fragen, die für Wahlentscheidungen in Demokratien von höchster Relevanz sind.
Wie können wir Datenkompetenz fördern?
Wenn Datenkompetenz ein essenzielles Gut für mündige Bürger*innen ist, so stellt sich die Fragen, wie sich diese Fähigkeit effektiv fördern lässt. Eine einzelne Massnahme ist dabei nicht hinreichend, die Verbesserung der Datenkompetenz in der Bevölkerung erfordert eine breite Palette von Initiativen und Partnerschaften auf internationaler, nationaler und lokaler Ebene. Ein zentraler Ansatz läuft dabei über das Bildungssystem, beispielsweise indem Datenkompetenz als integraler Bestandteil von Lehrplänen oder als eigenes Schulfach von der Grundschule bis hin zur Hochschule eingeführt wird. Als Alternative zu einem separaten, zusätzlichen Schulfach könnte der kritische Umgang mit Statistiken in die bestehenden Fächer integriert werden. Statistische Kompetenz ist keine monodisziplinäre Angelegenheit etwa der Mathematik, sondern erfordert die Kombination mathematischer, natur- und sozialwissenschaftlicher Fertigkeiten. Durch fachübergreifende Absprachen könnte gewährleistet werden, dass sich die eingeübten Strategien bestmöglich ergänzen: Wenn im Mathematikunterricht etwa das Lesen von Statistiken trainiert wird, könnte der Politik- oder Geschichtsunterricht einen kritischen Blick für die politische Instrumentalisierung von Statistiken schärfen. Bildungsinstitutionen sollten Lehrpersonen mit den erforderlichen Fähigkeiten und Ressourcen ausstatten, um Datenkompetenz effektiv zu vermitteln. Nationale statistische Ämter sollten dabei verstärkt mit Bildungseinrichtungen zusammenarbeiten und damit eine aktivere Rolle bei der Förderung von Datenkompetenz einnehmen.
Darüber hinaus sollten öffentliche Institutionen einen Beitrag dazu leisten, die statistische Bildung in der Bevölkerung zu verbessern. Dabei stellen Online-Angebote eine niedrigschwellige Möglichkeit dar, um die Bevölkerung mit dem Thema Datenkompetenz in Berührung zu bringen.[10] Ein Beispiel ist der Blog «Unstatistik des Monats» des Leibniz-Instituts für Wirtschaftsforschung: Ein vierköpfiges Team mit ökonomischer, psychologischer und statistischer Kompetenz kommentiert hier jeden Monat eine Statistik, die auf den ersten Blick plausibel erscheinen mag, aber irreführende Informationen verbreitet.[11] Auf diese Weise trägt «Unstatistik des Monats» allgemein dazu bei, den kritischen Blick für Statistiken zu schärfen – und entlarvt konkrete statistische Fehleinschätzungen.
Solche bildungspolitischen Initiativen können ergänzt werden durch nationale oder gar internationale Projekte: Die britische Royal Statistical Society hat es sich beispielsweise zur Aufgabe gemacht, die Datenkompetenz in der Bevölkerung zu verbessern, indem sie Lehrmaterialien bereitstellt oder mit Lehrpersonen in Austausch tritt.[12] Das Schweizerische Bundesamt für Statistik könnte diesem Beispiel folgen und Ressourcen bereitstellen sowie Schulungen anbieten, um die Datenkompetenz in verschiedenen Bevölkerungsgruppen zu fördern. Im Schulungsangebot des Kompetenzzentrums für Datenwissenschaft ist diese Interventionsmöglichkeit bereits angelegt und könnte weiter ausgebaut werden, um eine grössere Reichweite zu erzielen: Zurzeit richtet sich das Angebot nur an den öffentlichen Sektor und an Verwaltungen.[13] Auch auf internationaler Ebene lässt sich statistische Kompetenz fördern: Die Vereinten Nationen unterstützen ebenfalls verschiedene Initiativen zur Verbesserung der weltweiten Datenkompetenz. Besonders erwähnenswert ist hier das «International Statistical Literacy Project» (ISLP), welches unter der Führung der «International Association for Statistics Education» (IASE) arbeitet und als internationales Programm zur Förderung von Datenkompetenz in dieser Form einzigartig ist. Das ISLP organisiert Wettbewerbe und stellt Bildungsmaterialien bereit, was eine effektive Methode darstellt, die Datenkompetenz bei Schüler*innen zu verbessern.[14]
Eine datenkompetente Gesellschaft zu schaffen, erfordert eine koordinierte Anstrengung von Bildungseinrichtungen, nationalen Regierungen, internationalen Verbänden, Medien und der breiten Öffentlichkeit. Statistiken basieren auf Vorannahmen, die die Datenerhebung, -analyse, -interpretation und -vermittlung beeinflussen und ein bestimmtes Narrativ schaffen, das politisch instrumentalisiert werden kann. Bildungsinitiativen können auf verschiedenen Ebenen intervenieren, um in der breiten Bevölkerung den kritischen Blick auf Statistiken zu schärfen. Statistische Kompetenz ist eine grundlegende Voraussetzung für politische Mündigkeit, die angesichts der Allgegenwart von Statistiken und Big Data stetig an Bedeutung gewinnt. Sie versetzt Bürger*innen in die Lage, Nonsens-Korrelationen und irreführende Corona-Statistiken eigenständig einer kritischen Analyse zu unterziehen.
Fussnoten
Siehe zum Beispiel https://www.tylervigen.com/spu...
Williamson, Elizabeth J.; Walker, Alex J.; Bhaskaran, Krishnan u.a.: OpenSAFELY: factors associated with COVID-19 death in 17 million patients, in: Nature 584 (7821), 2020, S. 430–436. DOI: https://doi.org/10.1038%2Fs41586-020-2521-4; van Westen-Lagerweij, Naomi A. et al.: Are smokers protected against SARS-CoV-2 infection (COVID-19)? The origins of the myth, in: npj Primary Care Respiratory Medicine 31 (10), 2021. DOI: https://doi.org/10.1038/s41533...
Engel, Joachim et al.: Zivilstatistik: Konzept einer neuen Perspektive auf Data Literacy und Statistical Literacy, in: AStA Wirtschafts- und Sozialstatistisches Archiv 13, 2019, S. 213-244, hier S. 216f. DOI: https://doi.org/10.1007/s11943...
Vgl. Schiller, Achim; Engel, Joachim: The Importance of Statistical Literacy for Democracy - Civic-Education through Statistics, in: Kovács, Péter (Hg.): Challenges and Innovations in Statistics Education, 2018.
Vgl. https://www.boeckler.de/de/boeckler-impuls-armut-keine-folge-der-statistik-10660.htm [07.09.2023]
Vgl. https://www.nytimes.com/2018/03/17/us/politics/cambridge-analytica-trump-campaign.html; https://www.theguardian.com/uk-news/2018/mar/23/leaked-cambridge-analyticas-blueprint-for-trump-victory
Vgl. https://www.rwi-essen.de/presse/wissenschaftskommunikation/unstatistik [07.09.2023]
Autor*innen
Laura Betschka studiert im Bachelor Volkswirtschaftslehre an der
Humboldt-Universität zu Berlin und arbeitet im Bundesministerium für Gesundheit. Sie ist Geförderte der Studienstiftung des Deutschen Volkes.

Anna studiert Geschichte und Philosophie an der Universität Bern und ist Geförderte der Schweizerischen Studienstiftung.
Die Beiträge auf dem Reatch-Blog geben die persönliche Meinung der Autor*innen wieder und entsprechen nicht zwingend derjenigen von Reatch oder seiner Mitglieder.
Comments (0)