

Dieser Beitrag wurde im Rahmen von Scimpact geschrieben. Scimpact ist das Förderprogramm von Reatch für junge Menschen, die Wissenschaft in gesellschaftliche Debatten einbringen wollen.
Eine 50-jährige Frau ohne Symptome geht routinemässig zu einem Mammographie-Screening. Der Test ist positiv. Wie gross ist die Wahrscheinlichkeit, dass diese Frau tatsächlich an Brustkrebs erkrankt ist: 9 von 10, 8 von 10, 1 von 10oder 1 von 100? Diese Frage wurde an einer ärztlichen Fortbildung an eine Gruppe von GynäkologInnen gerichtet. Nur etwa 20% der ÄrztInnen antworteten richtig - dies ist weniger, als wenn alle teilnehmenden Fachpersonen zufällig auf eine Antwort getippt hätten.[1] Erschreckend, nicht?
«Wer misst misst Mist.» Dieses saloppe Sprichwort regt an, darüber nachzudenken, was eigentlich gemessen wird und wie genau. Denn jede Messung oder Test unterliegt einem gewissen Fehler. Davor sind auch medizinische Tests nicht gefeit. Deshalb ist es wichtig zu wissen, wie gross der zu erwartende Fehler ist, um dies in die Abwägung möglicher Konsequenzen des Testresultats miteinzubeziehen.
Für medizinische Tests, welche positiv oder negativ ausfallen, gibt es vier mögliche Ausgänge. Zum einen die «Korrekten»: richtig-positiv und richtig-negativ (die Person weist das Merkmal auf und erhält ein positives Testresultat und die Person weist das Merkmal nicht auf und der Test ist negativ). Weiter gibt es auch zwei «falsche Ausgänge»: falsch-positiv und falsch-negativ (vgl. Tabelle 1). Basierend auf diesen vier Möglichkeiten gibt es für die Aussagekraft von medizinischen Tests zwei einschlägige Parameter, die Sensitivität und die Spezifität.

Sensitivität Die Sensitivität gibt an, wie oft ein Test eine korrekte Aussage bei Personen mit einem spezifischen Merkmal macht. Die Sensitivität vom Mammographie-Screening liegt bei 90% [1]: 9 von 10 Frauen, welche Brustkrebs haben, erhalten ein positives Testresultat. Im Gegenzug bedeutet es, dass 10% der Personen mit Brustkrebs übersehen werden. Dies wir die Falsch-negativ-Rate genannt, weil der Test negativ ist, was jedoch falsch ist.
Spezifität Komplementär zur Sensitivität gibt die Spezifität an, wie oft ein Test eine korrekte Aussage bei Personen ohne ein spezifisches Merkmal macht. Beim Mammographie-Screening liegt die Spezifität bei 91%. [1] Das heisst, dass 91% der Frauen, welche am Screening teilnehmen und kein Brustkrebs haben, ein negatives Testresultat erhalten. Es bedeutet aber auch, dass 9% der teilnehmenden Personen ohne Brustkrebs positiv getestet werden. Dieser Anteil wird die Falsch-positiv-Rate genannt, weil der Test positiv ausfällt, aber die Person das Merkmal nicht aufweist.
Prävalenz Ein dritter Parameter, welcher nötig ist, um zur richtigen Antwort zur Einstiegsfrage zu gelangen, ist die Prävalenz. Sie gibt an, wie viele Personen einer Population ein Merkmal aufweisen. In diesem Beispiel ist das Merkmal Brustkrebs. Bei Frauen liegt die Prävalenz für Brustkrebs bei 1% oder in anderen Worten: 10 von 1'000 Frauen sind betroffen. [1]
Positiver Vorhersagewert Nun werden die obigen drei Teile zusammengesetzt, denn der Positive Vorhersagewert oder auch positive predictive value (PPV) liefert die Antwort zur Frage, wie gross die Wahrscheinlichkeit erkrankt zu sein ist, wenn der Test positiv ausfällt. Der PPV ist die Anzahl Personen, welche positiv getestet wurden und tatsächlich das Merkmal aufweisen (richtig-positive Tests), gemessen an der Gesamtanzahl der positiven Tests (egal, ob die Person das Merkmal aufweist oder nicht). Ideal wäre ein PPV von 1, denn dies bedeutet, dass alle Personen, welche ein positives Testresultat erhalten auch tatsächlich das Merkmal aufweisen.
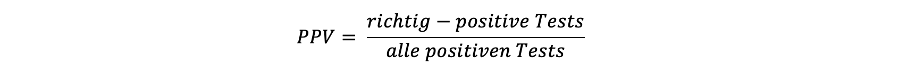
Um die Anzahl richtig-positiver Tests zu erhalten, wird die Gesamtmenge der teilnehmenden Personen mithilfe der Prävalenz in eine Gruppe von Personen mit Merkmal und solche ohne unterteilt. Anschliessend wird in der Gruppe der Personen mit Merkmal mit der Sensitivität berechnet, wie viele dieser Personen auch tatsächlich als mit Merkmal beziehungsweise erkrankt erkannt werden (positives Ergebnis). Angewendet auf das Mammographie-Beispiel ergibt das folgendes: Die Prävalenz liegt bei 1% und wir betrachten eine Population von 1'000 Frauen. Somit sind 10 Personen an Brustkrebs erkrankt. Die Sensitivität des Tests liegt bei 90%. Daraus folgt, dass 9 dieser 10 Personen korrekt als erkrankt erkannt werden (siehe auch Abbildung 1). Dies ist die Anzahl der richtig-positiven Testresultate.

Nun zum zweiten Teil der Rechnung: Alle positiven Tests sind die Summe der richtig-positiven Tests und der falsch-positiven Tests. Um die Anzahl der falsch-positiven Tests zu ermitteln, wird die Population wieder mithilfe der Prävalenz in eine Gruppe mit und eine ohne Merkmal unterteilt. Nur liegt dieses Mal der Fokus auf der Gruppe ohne Merkmal. Mit der Spezifität wird die Anzahl der Personen bestimmt, welche das Merkmal nicht aufweisen und ein negatives Testergebnis erhalten (richtig-negativ). Am Beispiel des Mammographie-Screenings sieht dies folgendermassen aus: Die Prävalenz liegt bei 1%, da nun die gesunden Personen von Interesse sind, werden in der Population von 1'000 Personen die restlichen 99% (also 990 Personen) betrachtet. Die Spezifität gibt an, wie viele dieser 990 Personen korrekt als gesund erkannt werden. Gesucht ist jedoch die Anzahl Personen, welche fälschlicherweise als krank getestet werden (falsch-positiv). Deshalb wird die Falsch-positiv-Rate (= 1 – Spezifität) verwendet. Diese beträgt 9%. Also werden von den 990 gesunden Personen etwa 89 Personen fälschlicherweise positiv getestet.
Die Puzzleteile werden nun zusammengesetzt:
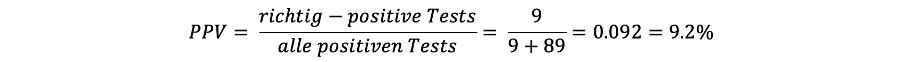
Der Positive Vorhersagewert liegt somit bei rund 9%. Dies bedeutet, dass lediglich etwa 1 von 10 beim Mammographie-Screening positiv getesteten Personen tatsächlich an Brustkrebs erkrankt sind. Erstaunlich, nicht?
Base Rate Fallacy Obwohl die Sensitivität und die Spezifität je bei circa 90% liegen, scheint der Positive Vorhersagewert relativ niedrig. Dieser Zusammenhang wird auch Prävalenzfehler oder Base Rate Fallacy genannt. [2] Das Wort Fehler bezieht sich dabei nicht auf die Berechnung an sich, sondern auf die menschliche Beurteilung des Einflusses der Prävalenz. Folgendes Beispiel soll den Einfluss der Prävalenz auf die Positive Vorhersagerate veranschaulichen: Angenommen, die Prävalenz liegt bei 10% anstelle 1%. Damit wären bei der gleichen betrachteten Population von 1'000 Personen 90 Tests richtig-positiv und 81 Tests falsch-positiv. Insgesamt läge der PPV dann bei knapp über 50%. In anderen Worten: Bereits jede zweite Person, welche ein positives Testresultat erhält, ist auch tatsächlich erkrankt. Im Vergleich zu den knapp 10% bei einer Prävalenz von 1% stellt das ein massiver Unterschied dar. [3]
Wiederholtes Testen Ein Schlüssel für eine höhere Positive Vorhersagerate bildet die Prävalenz. Diese wird jeweils abgeschätzt und ist prinzipiell fix. Prinzipiell ist in diesem Fall auf die jeweilige Testgruppe bezogen. Wenn Personen an einem Screening-Verfahren teilnehmen, bezieht sich die Prävalenz auf die gesamte Population. Wenn jedoch alle positiv getesteten Personen noch einmal dem gleichen Test unterzogen werden, ändert sich die Prävalenz (sie ist im Vergleich höher) und die Positive Vorhersagerate steigt somit ebenfalls. Wiederholtes testen ist somit eine Möglichkeit, die Vorhersagegenauigkeit zu erhöhen.
Fazit Diese Prinzipien, welche am Beispiel des Mammographie-Screenings dargestellt wurden, gelten im Allgemeinen für medizinische Tests. Dazu gehören auch der PSA-Test für Prostatakrebs, HIV-Tests, Sars-CoV-2-Tests oder der Schnelltest für Laktoseintoleranz. Die Sensitivität und Spezifität ist für alle Tests gegeben, jedoch hängt die Prävalenz von der jeweiligen Untersuchungsgruppe ab. Somit kann bei einem positiven Testergebnis ein zweiter Test mehr Klarheit bringen.
Insgesamt ist es wichtig, Fachpersonen und getestete Personen zu informieren, was ein positives beziehungsweise negatives Testergebnis bedeutet oder eben nicht. Basierend darauf kann eine Entscheidung, ob ein Test (beispielsweise bei einem Screening) individuell sinnvoll ist, gefällt werden. Dies kann vor allem dann wichtig sein, falls bei einem positiven Testergebnis einschneidende Folgeuntersuchungen oder Operationen angeordnet werden. Ausserdem sind die zu testenden Personen mit dem Wissen, dass das Ergebnis nicht in Stein gemeisselt ist, psychisch besser auf das Resultat vorbereitet. Durch einen transparenten Informationsfluss kann gewährleistet werden, dass jede Person eine Entscheidung basierend auf ihren eigenen Umständen und Meinung fällen kann.
Quellen
[1] G. Gigerenzer, J. Kuoni, und R. Ritschard, «Was Ärzte wissen müssen», Swiss Med. Forum ‒ Schweiz. Med.-Forum, Bd. 15, Nr. 36, Sep. 2015, doi: 10.4414/smf.2015.02403.
[2] C. Glaser, «Prävalenzfehler», in Risiko im Management: 100 Fehler, Irrtümer, Verzerrungen und wie man sie vermeidet, C. Glaser, Hrsg., Wiesbaden: Springer Fachmedien Wiesbaden, 2019, S. 293–296. doi: 10.1007/978-3-658-25835-1_74.
[3] H. K. Strick, «Paradoxien im Zusammenhang mit medizinischen Schnelltests», in Stochastische Paradoxien, H. K. Strick, Hrsg., Wiesbaden: Springer Fachmedien Wiesbaden, 2020, S. 15–17. doi: 10.1007/978-3-658-29583-7_4.
Autor*innen

Anik studiert Gesundheitswissenschaften und Technologie an der ETH Zürich. Die Anwendung von Engineering in der Medizin, molekulare Mechanismen, welche Krankheiten zu Grunde liegen, aber auch der Einfluss von Bewegung auf den menschlichen Körper sind zentrale Themen. Bei Reatch wirkt Anik als Scimpact Fellow mit.
Die Beiträge auf dem Reatch-Blog geben die persönliche Meinung der Autor*innen wieder und entsprechen nicht zwingend derjenigen von Reatch oder seiner Mitglieder.
Comments (0)